为异构大数据运行环境构建高效数据处理服务管道
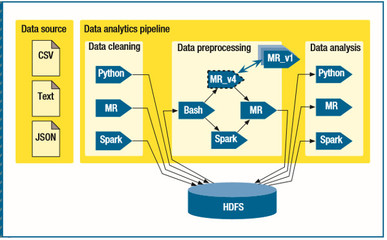
随着大数据技术的飞速发展,企业数据环境日益复杂,通常包含多种数据源、存储系统和计算框架,形成典型的异构大数据运行环境。在这样的背景下,构建一个统一、高效、可靠的数据处理服务管道,成为释放数据价值、驱动业务智能的关键。
一、异构大数据环境的挑战与机遇
异构大数据环境通常意味着数据可能存储在关系型数据库、NoSQL数据库、数据湖、数据仓库乃至云存储等不同系统中;计算任务可能涉及批处理、流处理、交互式查询和机器学习等多种范式,运行在Hadoop、Spark、Flink、云原生服务等不同平台上。这种多样性带来了灵活性,但也引入了显著的复杂性:数据孤岛、格式不一致、处理逻辑分散、运维成本高昂。
构建统一的数据管道,正是为了应对这些挑战。它将分散的数据流动与处理任务整合到一个可管理、可观测的框架中,实现数据从源头到消费端的无缝、高效流转,确保数据的时效性、质量与一致性。
二、数据处理服务管道的核心架构
一个面向异构环境的数据处理服务管道,其架构设计应遵循松耦合、可扩展和容错性原则。核心组件通常包括:
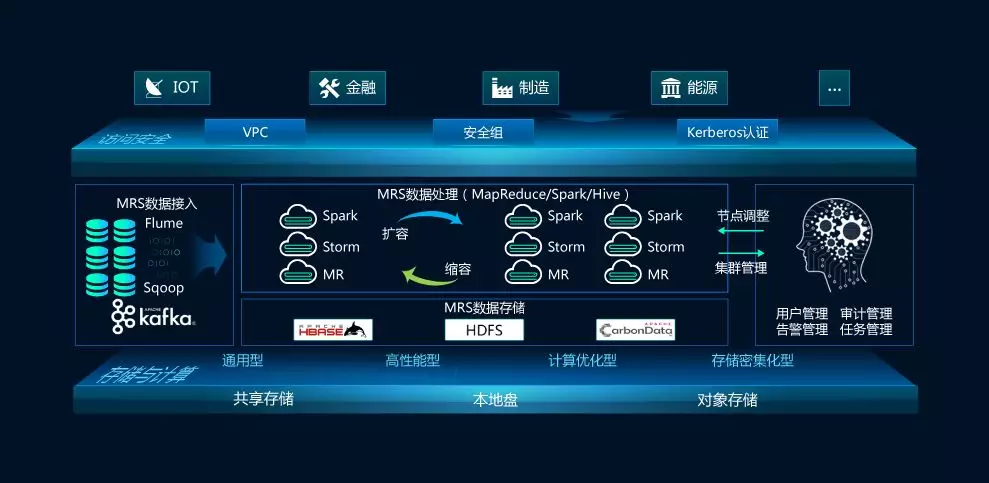
- 统一的摄入层:负责从各类数据源(如数据库日志、消息队列、文件系统、API接口)实时或批量抽取数据。适配器模式是关键,通过不同的连接器(Connector)屏蔽底层源系统的差异,将数据转换为统一的中间格式(如Avro、Parquet)或事件流。
- 强大的处理引擎层:这是管道的“大脑”。它需要支持多种处理模式:
- 流处理:对无界数据流进行实时清洗、转换、聚合与异常检测,适用于监控、实时推荐等场景。
- 批处理:对大规模历史数据进行复杂的ETL/ELT操作,支持SQL、代码等多种开发方式。
* 混合处理:结合流批一体(如Flink)或Lambda/Kappa架构,灵活应对不同需求。
该层应能灵活调度任务到不同的底层计算集群(如Kubernetes, YARN),实现资源的统一管理与弹性伸缩。
- 可靠的消息与存储中间层:作为管道各阶段间的缓冲与解耦,高吞吐、可持久化的消息队列(如Kafka, Pulsar)至关重要。数据湖或对象存储可作为原始数据和中间结果的统一存储层,支持低成本的海量数据存储与多引擎分析。
- 灵活的服务与输出层:将处理后的数据按需输出到目标系统,如数据仓库(ClickHouse, Snowflake)、分析数据库、缓存(Redis)、API服务或机器学习平台,以支持下游的BI报表、数据应用和AI模型训练。
- 统一的元数据管理与数据治理:贯穿整个管道,对数据资产、血缘关系、数据质量、访问权限和安全策略进行集中管理,确保数据的可信、可用与合规。
三、构建数据处理服务的关键技术策略
- 采用标准化与抽象化:定义统一的数据模型(如Data Mesh中的数据产品概念)和API接口,减少系统间的直接依赖。使用容器化(Docker)和编排技术(Kubernetes)封装处理任务,实现环境一致性与快速部署。
- 拥抱云原生与Serverless:利用云平台提供的托管服务(如AWS Glue, Google Dataflow, Azure Data Factory)构建管道,可以显著降低运维负担,并享受自动扩缩容、按需付费等优势。
- 实现可观测性与自动化:管道必须具备完善的监控(指标、日志、追踪)、告警和自愈能力。通过自动化的工作流编排工具(如Apache Airflow, Dagster, Prefect)来定义、调度和监控复杂的数据处理DAG(有向无环图)。
- 保障数据质量与安全:在管道的关键节点嵌入数据质量检查规则(如完整性、准确性、唯一性校验),并实施端到端的数据加密、脱敏和细粒度访问控制。
- 支持演进与协作:管道设计应允许新数据源、新处理逻辑的平滑接入。在团队协作上,可以借鉴DataOps理念,实现数据处理代码的版本控制、CI/CD和协同开发。
四、
为异构大数据环境构建数据处理服务管道,是一项系统性工程,其目标不仅是连接“数据孤岛”,更是打造一个敏捷、智能、可信的数据供应链。成功的管道能够将复杂的技术栈整合为一项稳定的“服务”,让业务人员和数据科学家能够更专注于从数据中获取洞察,而非纠结于数据获取与准备的繁琐过程。随着人工智能的深入融合,具备智能编排、自动优化和主动治理能力的“自治数据管道”将成为新的趋势,进一步推动企业数据驱动能力的质变。