Python网络爬虫实战 Scrapy与Beautiful Soup的使用及数据处理技巧
网络爬虫是获取互联网数据的重要工具,Python因其丰富的库和简洁的语法成为爬虫开发的首选语言。在众多爬虫工具中,Scrapy和Beautiful Soup各具特色,结合使用能高效完成数据采集与处理任务。
一、Scrapy框架的使用
Scrapy是一个功能强大的爬虫框架,适合大规模、结构化的数据采集。
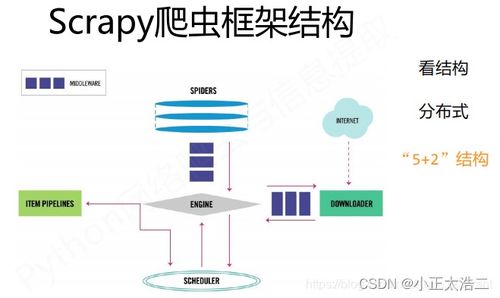
1. 基础架构
- 引擎(Engine):控制数据流,协调各组件工作
- 调度器(Scheduler):管理请求队列
- 下载器(Downloader):获取网页内容
- 爬虫(Spider):定义爬取逻辑和数据提取规则
- 项目管道(Pipeline):处理提取的数据
2. 快速入门
`python
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example'
start_urls = ['http://example.com']
def parse(self, response):
# 提取数据
title = response.css('h1::text').get()
yield {'title': title}
# 跟进链接
for link in response.css('a::attr(href)').getall():
yield response.follow(link, self.parse)`
3. 高级特性
- 中间件:自定义请求/响应处理
- Item Loader:结构化数据提取
- Feed导出:支持JSON、CSV等多种格式
- 去重过滤:自动避免重复爬取
二、Beautiful Soup的使用
Beautiful Soup是灵活的HTML/XML解析库,适合小规模或结构不规则的页面。
1. 基础解析
`python
from bs4 import BeautifulSoup
import requests
html = requests.get('http://example.com').text
soup = BeautifulSoup(html, 'lxml')
多种选择器
soup.find('div', class='content')
soup.select('div.content > p')
soup.findall(text='特定文本')`
2. 解析器选择
- lxml:速度快,容错性好(推荐)
- html.parser:Python内置,无需额外安装
- html5lib:容错性最好,速度较慢
三、数据处理技巧
1. 数据清洗
`python
import re
from datetime import datetime
去除空白字符
def clean_text(text):
return re.sub(r'\s+', ' ', text).strip()
日期标准化
def normalizedate(datestr):
formats = ['%Y-%m-%d', '%d/%m/%Y', '%b %d, %Y']
for fmt in formats:
try:
return datetime.strptime(date_str, fmt).date()
except:
continue
return None`
2. 数据验证
`python
import pandas as pd
from cerberus import Validator
schema = {
'title': {'type': 'string', 'required': True},
'price': {'type': 'float', 'min': 0},
'url': {'type': 'string', 'regex': '^https?://'}
}
validator = Validator(schema)
if validator.validate(data):
# 数据有效
pass`
3. 数据存储
`python
# 存储到CSV
import csv
with open('data.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(data_list)
存储到数据库
import sqlite3
conn = sqlite3.connect('data.db')
cursor = conn.cursor()
cursor.execute('''CREATE TABLE IF NOT EXISTS items
(title TEXT, price REAL, url TEXT)''')`
四、数据处理服务设计
1. 服务架构
数据采集层(Scrapy/Requests) → 数据解析层(Beautiful Soup) →
数据处理层(清洗/验证) → 数据存储层(数据库/文件) →
数据API层(RESTful接口)2. 错误处理机制
- 网络请求重试
- 解析失败日志记录
- 数据质量监控
- 异常数据隔离
3. 性能优化
`python
# 使用aiohttp异步请求
import aiohttp
import asyncio
async def fetch(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.text()
使用线程池
from concurrent.futures import ThreadPoolExecutor
with ThreadPoolExecutor(maxworkers=10) as executor:
results = executor.map(processdata, data_list)`
五、最佳实践建议
- 遵守robots.txt:尊重网站爬取规则
- 设置合理延迟:避免对目标网站造成压力
- 使用User-Agent:模拟真实浏览器访问
- 处理反爬机制:合理使用代理IP和Cookie
- 数据去重:避免存储重复数据
- 定期维护:更新选择器,适应网站改版
六、完整示例:电商价格监控系统
`python
import scrapy
from bs4 import BeautifulSoup
import pandas as pd
from datetime import datetime
class PriceMonitorSpider(scrapy.Spider):
name = 'pricemonitor'
def startrequests(self):
urls = ['http://example.com/products']
for url in urls:
yield scrapy.Request(url, callback=self.parselist)
def parselist(self, response):
soup = BeautifulSoup(response.text, 'lxml')
products = soup.select('.product-item')
for product in products:
item = {
'name': product.selectone('.name').text.strip(),
'price': float(product.selectone('.price').text.replace('¥', '')),
'url': response.urljoin(product.selectone('a')['href']),
'crawltime': datetime.now().isoformat()
}
yield item
# 在settings.py中配置数据管道
ITEM_PIPELINES = {
'project.pipelines.DataCleanPipeline': 300,
'project.pipelines.DatabasePipeline': 800,
}
`
七、
Scrapy和Beautiful Soup是Python爬虫生态中的黄金组合。Scrapy适合构建完整的爬虫项目,提供完整的框架支持;Beautiful Soup则在小规模、快速开发的场景中表现出色。结合两者的优势,配合合理的数据处理流程,可以构建出高效、稳定的数据采集与处理服务。
在实际开发中,应根据具体需求选择合适工具,注重代码的可维护性和扩展性,同时遵守相关法律法规和网站使用条款,实现可持续的数据采集服务。